
We’re all pretty used to waiting a second or two for a search engine to load. For a person, that’s just a quick breath. But for an AI agent? That second is an absolute eternity. If you have an agent trying to complete a complex task that requires twenty sequential searches, you’re suddenly looking at nearly half a minute of just… waiting. It’s frustrating. It breaks the flow. This friction is the primary hurdle as we move toward the next generation of IoT Machine Learning. We are shifting away from sensors that simply report data and toward autonomous agents that can actually reason and act on it in real-time.
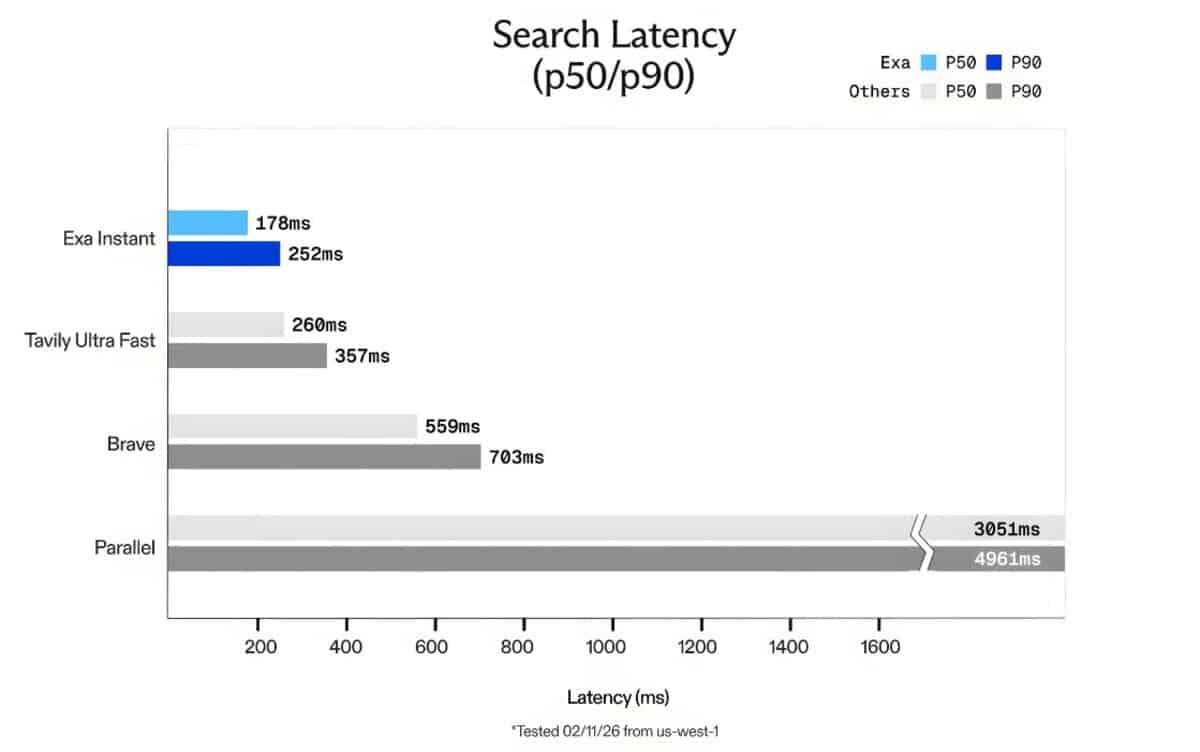
This is exactly what Exa Instant is trying to fix. They’ve managed to get search latency down to about 150ms—sometimes even as low as 100ms. It is a tool designed with machine workflows in mind, rather than just human eyes staring at a screen. In the context of the 2026 landscape, where billions of connected devices need to make split-second decisions, this kind of speed isn’t just a luxury—it’s the backbone of autonomy.
The Problem with Search Wrappers
Most of the “AI search” tools you see lately are actually just wrappers. They grab your query, toss it to an old-school engine like Google or Bing, scrape whatever comes back, and then hand it over. It’s a clunky process. Because those legacy engines weren’t built for high-speed API calls, they usually have a latency floor of around 700ms or more.
Exa didn’t do that. They built their own stack from the ground up using transformers and embeddings. It doesn’t just match keywords like “best laptop”; it understands the underlying intent of a query. This proprietary approach is how they’ve cut the overhead so drastically. This mirrors the broader evolution of the “Agentic Web,” where systems no longer just retrieve information but interpret intent to execute multi-step outcomes without human intervention. Think of it like the difference between wandering a massive library with a paper map versus having a librarian who already knows the exact shelf for every single sentence.
Does This Actually Change Anything?
You might wonder if 200ms really matters. If you’re building a voice assistant that needs to feel human, or a research agent that needs to verify facts in real-time, then yes, it matters immensely. In recent tests using the SealQA benchmark, Exa Instant performed significantly faster than alternatives like Tavily or Brave. When you consider how these agents will eventually manage everything from industrial supply chains to smart city grids, reducing that bottleneck is what allows a “connected sensor” to graduate into a truly “autonomous agent.”
It’s also surprisingly cheap—costing $5 for 1,000 requests. That price point actually makes it doable for developers to build “thoughtful” agents that check the web constantly, without having to worry about blowing the budget or watching the performance slow to a crawl.
What’s your take on this? Are we entering an era where AI agents will know more about the current web than we do, simply because they can search it faster? Let us know your thoughts in the comments and follow us on Facebook, X (Twitter), or LinkedIn for more on the evolving AI landscape.
Sources:
- www.exa.ai/blog/exa-instant
- www.marktechpost.com/2026/02/13/exa-ai-introduces-exa-instant-a-sub-200ms-neural-search-engine-designed-to-eliminate-bottlenecks-for-real-time-agentic-workflows/
- www.exa.ai/blog/exa-api-2-1

Do You Still Need a Website in 2026? Google’s Search Team Weighs In
Google Dominance Grows in Azerbaijan as Yandex Market Share Slumps